Hello World With Keras
Page content
KerasでMNIST手書き数字を分類する。
from keras.datasets import mnist
from keras import models
from keras import layers
from keras.utils import to_categorical
import matplotlib.pyplot as plt
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
network = models.Sequential()
# 最初の隠れ層は512を設定する, 活性化関数をReluを設定する
network.add(layers.Dense(512, activation="relu", input_shape=(28*28,)))
# 出力10個、0-9まで10個の出力あるから
network.add(layers.Dense(10, activation="softmax"))
network.compile(optimizer="rmsprop", loss="categorical_crossentropy", metrics=["accuracy"])
train_images = train_images.reshape((60000, 28*28))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28*28))
test_images = test_images.astype("float32") / 255
# 整数のクラスベクトルから2値クラスの行列への変換します.
# https://keras.io/ja/utils/#to_categorical
categorical_train_labels = to_categorical(train_labels)
categorical_test_labels = to_categorical(test_labels)
# fit the model to its training data
# the network iterate on the training data in mini-batches of 128 samples, 5 times over
# each iteration over all the training data is called an epoch
history = network.fit(train_images, categorical_train_labels, epochs=5, batch_size=128)
test_loss, test_acc = network.evaluate(test_images, categorical_test_labels)
print('test_acc:', test_acc) Using TensorFlow backend.
Epoch 1/5
60000/60000 [==============================] - 9s 142us/step - loss: 0.2532 - acc: 0.9277
Epoch 2/5
60000/60000 [==============================] - 10s 165us/step - loss: 0.1043 - acc: 0.9689
Epoch 3/5
60000/60000 [==============================] - 8s 131us/step - loss: 0.0696 - acc: 0.9795
Epoch 4/5
60000/60000 [==============================] - 9s 158us/step - loss: 0.0502 - acc: 0.9851
Epoch 5/5
60000/60000 [==============================] - 8s 139us/step - loss: 0.0374 - acc: 0.9884
10000/10000 [==============================] - 1s 60us/step
test_acc: 0.9801
to_categoricalの役割を見てみる。実際にOne Hot Encodeのことをやっている。
# train_labels[0]は 5
digit = train_labels[0]
categorical_digit = to_categorical(digit)
print('{}: {}'.format(digit, categorical_digit))
# train_labels[2]は 4
digit = train_labels[2]
categorical_digit = to_categorical(digit)
print('{}: {}'.format(digit, categorical_digit))5: [0. 0. 0. 0. 0. 1.]
4: [0. 0. 0. 0. 1.]
network.compile(..., metrics=["accuracy"])のオプションにモデルの評価はaccuracyを書いてある。多クラス分類の問題なので、実際categorical_accuracyのことを指している。
network.compile(optimizer="rmsprop", loss="categorical_crossentropy", metrics=["categorical_accuracy"])
network.fit()関数の戻り値historyについて、調べてみる。accだんだん上がっていることを図で確認できる。逆にloss損失値はだんだん下がることも確認できる。
print(history.history.keys())
print(history.history["loss"])
print(history.history["acc"])dict_keys(['loss', 'acc'])
[0.2532248511552811, 0.1042881952504317, 0.06958325177530447, 0.05017872037192186, 0.037415427959462004]
[0.9277333333333333, 0.9689499999682109, 0.9794833333015441, 0.9850999999682108, 0.9883833333333333]
for key in history.history.keys():
plt.plot(range(1, 6), history.history[key])
plt.legend(list(history.history.keys()), loc="upper left")
plt.show()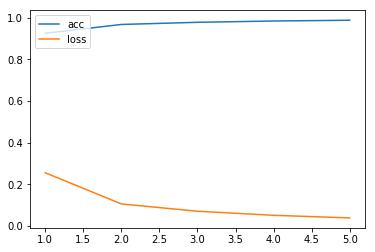
Dropoutを利用する場合隠れそうの後ろにDropout rateを追加するだけ。
# 最初の隠れ層は512を設定する, 活性化関数をReluを設定する
network.add(layers.Dense(512, activation="relu", input_shape=(28*28,)))
network.add(layers.Dropout(0.2))
今回モデルを学習する際のoptimizerがrmspropを使っていますが、もしsgdを使うと、epochは同じ5で設定する場合、精度は90%ぐらいにしかできない。同じ精度を得るためにはepochの回数をもっとあげる(例えば40)必要がある。
network.compile(optimizer="sgd", loss="categorical_crossentropy", metrics=["accuracy"])